Now Reading: Python Synthesizer: Build Your Own Sound Generator with pyaudio and numpy
1
-
01
Python Synthesizer: Build Your Own Sound Generator with pyaudio and numpy
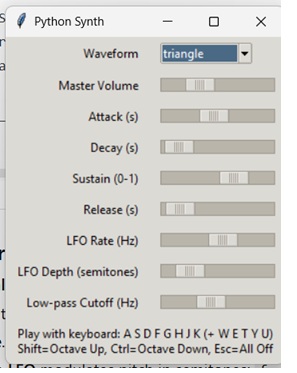
Python Synthesizer: Build Your Own Sound Generator with pyaudio and numpy
It’s a real-time, polyphonic soft-synth with:
- Waveforms: Sine / Square / Saw / Triangle / Noise
- ADSR envelope (Attack, Decay, Sustain, Release)
- LFO vibrato (rate & depth)
- One-pole low-pass filter (cutoff)
- Master volume
- Computer-keyboard “piano” (A–K with black keys on W/E/T/Y/U)
Everything is in one file and runs cross-platform.
Requirements
pip install sounddevice numpy
Windows may need the Microsoft Visual C++ Redistributable.
Linux may need PortAudio dev libs:sudo apt-get install portaudio19-dev.
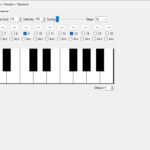
Controls (Keyboard)
White keys: A S D F G H J K
Black keys: W E T Y U
- Hold Shift for an octave up, Ctrl for an octave down
- Press Esc to stop all notes
The Code
#!/usr/bin/env python3
"""
GUI Polyphonic Synthesizer (Tkinter + sounddevice + NumPy)
Features:
- Waveforms: sine/square/saw/triangle/noise
- Polyphony (up to MAX_VOICES)
- ADSR envelope
- LFO vibrato (rate/depth)
- One-pole low-pass filter
- Master volume
- Computer keyboard piano: A S D F G H J K (white); W E T Y U (black)
Shift = octave up, Ctrl = octave down, Esc = all notes off
Dependencies:
pip install sounddevice numpy
"""
import math
import time
import threading
import numpy as np
import sounddevice as sd
import tkinter as tk
from tkinter import ttk
# ---------------- Audio / Synth Engine ----------------
SAMPLE_RATE = 48000
BLOCK = 256
MAX_VOICES = 12
# Key-to-semitone mapping (relative to base MIDI note)
KEYMAP = {
'a': 0, # C
'w': 1, # C#
's': 2, # D
'e': 3, # D#
'd': 4, # E
'f': 5, # F
't': 6, # F#
'g': 7, # G
'y': 8, # G#
'h': 9, # A
'u': 10, # A#
'j': 11, # B
'k': 12, # C (next)
}
BASE_MIDI = 60 # C4
A4 = 440.0
def midi_to_freq(m):
return A4 * (2.0 ** ((m - 69) / 12.0))
def db_to_amp(db):
return 10 ** (db / 20.0)
class Voice:
"""
One voice with its own oscillator, envelope and release lifecycle.
"""
__slots__ = ("midi","freq","phase","env","state","t_in_state","released",
"last_sample")
def __init__(self, midi, freq):
self.midi = midi
self.freq = freq
self.phase = 0.0
self.env = 0.0
self.state = "attack" # attack -> decay -> sustain -> release -> dead
self.t_in_state = 0.0
self.released = False
self.last_sample = 0.0
class Synth:
def __init__(self):
# Parameters (shared, updated by GUI)
self.waveform = "sine"
self.master_gain = 0.3 # 0..1
self.attack = 0.01
self.decay = 0.10
self.sustain = 0.7
self.release = 0.20
self.lfo_rate = 5.0 # Hz
self.lfo_depth = 0.0 # semitones
self.cutoff_hz = 18000.0 # low-pass cutoff
self.base_midi = BASE_MIDI
# State
self.voices = {} # midi -> Voice
self.voice_order = [] # oldest first for stealing
self.lock = threading.Lock()
# Filter memory (one-pole)
self.lp_y = 0.0
self.lp_a = self._calc_alpha(self.cutoff_hz)
# LFO phase
self.lfo_phase = 0.0
# Audio stream
self.stream = sd.OutputStream(
samplerate=SAMPLE_RATE,
channels=1,
blocksize=BLOCK,
dtype="float32",
callback=self._callback)
self.stream.start()
def _calc_alpha(self, cutoff):
# One-pole low-pass smoothing factor
cutoff = max(10.0, min(cutoff, SAMPLE_RATE/2 - 100))
rc = 1.0 / (2.0 * math.pi * cutoff)
dt = 1.0 / SAMPLE_RATE
alpha = dt / (rc + dt)
return float(alpha)
def set_cutoff(self, hz):
self.cutoff_hz = float(hz)
self.lp_a = self._calc_alpha(self.cutoff_hz)
def note_on(self, midi):
with self.lock:
if midi in self.voices:
# restart envelope if already active
v = self.voices[midi]
v.state = "attack"
v.t_in_state = 0.0
v.released = False
return
if len(self.voices) >= MAX_VOICES:
# voice stealing: drop oldest
oldest = self.voice_order.pop(0)
self.voices.pop(oldest, None)
v = Voice(midi, midi_to_freq(midi))
self.voices[midi] = v
self.voice_order.append(midi)
def note_off(self, midi):
with self.lock:
v = self.voices.get(midi)
if v and not v.released:
v.state = "release"
v.t_in_state = 0.0
v.released = True
def all_notes_off(self):
with self.lock:
for v in self.voices.values():
v.state = "release"
v.released = True
v.t_in_state = 0.0
# ---- Oscillators ----
def osc(self, phase):
wf = self.waveform
if wf == "sine":
return math.sin(phase)
elif wf == "square":
return 1.0 if math.sin(phase) >= 0 else -1.0
elif wf == "saw":
# phase is 0..2π; map to -1..1 saw
return (phase / math.pi) - 1.0
elif wf == "triangle":
# triangle from saw
x = (phase / (2*math.pi)) % 1.0
return 4.0 * abs(x - 0.5) - 1.0
elif wf == "noise":
return np.random.uniform(-1.0, 1.0)
return 0.0
# ---- Envelope ----
def step_env(self, v: Voice, dt):
A, D, S, R = self.attack, self.decay, self.sustain, self.release
v.t_in_state += dt
if v.state == "attack":
if A <= 0:
v.env = 1.0
v.state = "decay"
v.t_in_state = 0.0
else:
v.env = min(1.0, v.t_in_state / A)
if v.env >= 1.0:
v.state = "decay"
v.t_in_state = 0.0
elif v.state == "decay":
if D <= 0:
v.env = S
v.state = "sustain"
v.t_in_state = 0.0
else:
# decay linearly from 1 -> S
t = min(1.0, v.t_in_state / D)
v.env = (1.0 - t) * 1.0 + t * S
if t >= 1.0:
v.state = "sustain"
v.t_in_state = 0.0
elif v.state == "sustain":
v.env = S
if v.released:
v.state = "release"
v.t_in_state = 0.0
elif v.state == "release":
if R <= 0:
v.env = 0.0
else:
# linear current -> 0 over R
t = min(1.0, v.t_in_state / R)
v.env = (1.0 - t) * v.env
if v.env <= 1e-4:
v.env = 0.0
# mark voice dead by removing it
return False
return True
def _callback(self, outdata, frames, time_info, status):
# Per audio block render
buf = np.zeros(frames, dtype=np.float32)
# Precompute LFO per-sample for vibrato (frequency modulation in semitones)
lfo_rate = max(0.0, float(self.lfo_rate))
lfo_depth = float(self.lfo_depth)
if lfo_rate <= 0 or lfo_depth == 0:
lfo = np.zeros(frames, dtype=np.float32)
else:
t = (np.arange(frames, dtype=np.float32) + 0) / SAMPLE_RATE
phase = (self.lfo_phase + (2*np.pi*lfo_rate)*t) % (2*np.pi)
lfo = np.sin(phase) * lfo_depth
self.lfo_phase = (self.lfo_phase + 2*np.pi*lfo_rate*frames/SAMPLE_RATE) % (2*np.pi)
dt = 1.0 / SAMPLE_RATE
dead_list = []
with self.lock:
voice_items = list(self.voices.items())
for midi, v in voice_items:
# Build per-sample oscillator for this voice
# Vibrato: modulate frequency by cents/semis -> freq * 2^(lfo/12)
# We'll update phase increment per-sample.
samples = np.empty(frames, dtype=np.float32)
phi = v.phase
base_freq = v.freq
env_ok = True
for i in range(frames):
# Envelope step at control rate (per-sample simple)
if (i == 0) or (i % 8 == 0): # lighten CPU: update env every 8 samples
env_ok = self.step_env(v, dt * 8 if i else dt)
if not env_ok:
dead_list.append(midi)
# fill remaining with zeros and break
samples[i:] = 0.0
break
# Instantaneous frequency with vibrato
f = base_freq * (2.0 ** (lfo[i] / 12.0))
inc = 2.0 * math.pi * f / SAMPLE_RATE
# Waveform sample
s = self.osc(phi)
# Apply envelope
s *= v.env
samples[i] = s
phi += inc
if phi > 2*math.pi:
phi -= 2*math.pi
v.phase = phi
buf += samples
# One-pole low-pass filter
if self.cutoff_hz < SAMPLE_RATE/2:
y = self.lp_y
a = self.lp_a
for i in range(frames):
y += a * (buf[i] - y)
buf[i] = y
self.lp_y = float(y)
# Master volume and soft limiting
buf *= float(self.master_gain)
# light soft-clip
np.tanh(buf, out=buf)
# Remove dead voices
if dead_list:
with self.lock:
for m in dead_list:
if m in self.voices:
self.voices.pop(m, None)
if m in self.voice_order:
self.voice_order.remove(m)
outdata[:, 0] = buf
# ---------------- GUI ----------------
class SynthGUI:
def __init__(self, root):
self.root = root
self.root.title("Python Synth")
self.synth = Synth()
self._octave = 0 # relative octave shift
self._build_ui()
self._bind_keys()
def _build_ui(self):
pad = dict(padx=10, pady=6)
frm = ttk.Frame(self.root)
frm.pack(fill="both", expand=True)
# Row 0: Waveform
ttk.Label(frm, text="Waveform").grid(row=0, column=0, sticky="e", **pad)
self.wave = tk.StringVar(value="sine")
cb = ttk.Combobox(frm, state="readonly", textvariable=self.wave,
values=["sine","square","saw","triangle","noise"], width=12)
cb.grid(row=0, column=1, sticky="w", **pad)
cb.bind("<<ComboboxSelected>>", lambda e: self._set_wave())
# Row 1: Master
ttk.Label(frm, text="Master Volume").grid(row=1, column=0, sticky="e", **pad)
self.vol = tk.DoubleVar(value=0.3)
vol_s = ttk.Scale(frm, from_=0.0, to=1.0, variable=self.vol,
command=lambda v: self._set_volume())
vol_s.grid(row=1, column=1, sticky="we", **pad)
# Row 2: ADSR
ttk.Label(frm, text="Attack (s)").grid(row=2, column=0, sticky="e", **pad)
self.attack = tk.DoubleVar(value=0.01)
ttk.Scale(frm, from_=0.0, to=2.0, variable=self.attack,
command=lambda v: self._set_adsr()).grid(row=2, column=1, sticky="we", **pad)
ttk.Label(frm, text="Decay (s)").grid(row=3, column=0, sticky="e", **pad)
self.decay = tk.DoubleVar(value=0.10)
ttk.Scale(frm, from_=0.0, to=2.0, variable=self.decay,
command=lambda v: self._set_adsr()).grid(row=3, column=1, sticky="we", **pad)
ttk.Label(frm, text="Sustain (0-1)").grid(row=4, column=0, sticky="e", **pad)
self.sustain = tk.DoubleVar(value=0.7)
ttk.Scale(frm, from_=0.0, to=1.0, variable=self.sustain,
command=lambda v: self._set_adsr()).grid(row=4, column=1, sticky="we", **pad)
ttk.Label(frm, text="Release (s)").grid(row=5, column=0, sticky="e", **pad)
self.release = tk.DoubleVar(value=0.20)
ttk.Scale(frm, from_=0.0, to=3.0, variable=self.release,
command=lambda v: self._set_adsr()).grid(row=5, column=1, sticky="we", **pad)
# Row 6: LFO
ttk.Label(frm, text="LFO Rate (Hz)").grid(row=6, column=0, sticky="e", **pad)
self.lfo_rate = tk.DoubleVar(value=5.0)
ttk.Scale(frm, from_=0.0, to=15.0, variable=self.lfo_rate,
command=lambda v: self._set_lfo()).grid(row=6, column=1, sticky="we", **pad)
ttk.Label(frm, text="LFO Depth (semitones)").grid(row=7, column=0, sticky="e", **pad)
self.lfo_depth = tk.DoubleVar(value=0.0)
ttk.Scale(frm, from_=0.0, to=2.0, variable=self.lfo_depth,
command=lambda v: self._set_lfo()).grid(row=7, column=1, sticky="we", **pad)
# Row 8: Filter
ttk.Label(frm, text="Low-pass Cutoff (Hz)").grid(row=8, column=0, sticky="e", **pad)
self.cutoff = tk.DoubleVar(value=18000.0)
ttk.Scale(frm, from_=200.0, to=float(SAMPLE_RATE/2 - 200),
variable=self.cutoff, command=lambda v: self._set_cutoff()).grid(row=8, column=1, sticky="we", **pad)
# Row 9: Info
info = ttk.Label(frm, text="Play with keyboard: A S D F G H J K (+ W E T Y U)\nShift=Octave Up, Ctrl=Octave Down, Esc=All Off")
info.grid(row=9, column=0, columnspan=2, sticky="we", **pad)
frm.columnconfigure(1, weight=1)
# initialize engine params
self._set_wave(); self._set_volume(); self._set_adsr(); self._set_lfo(); self._set_cutoff()
def _bind_keys(self):
self.root.bind("<KeyPress>", self._on_keydown)
self.root.bind("<KeyRelease>", self._on_keyup)
def _set_wave(self):
self.synth.waveform = self.wave.get()
def _set_volume(self):
self.synth.master_gain = float(self.vol.get())
def _set_adsr(self):
self.synth.attack = float(self.attack.get())
self.synth.decay = float(self.decay.get())
self.synth.sustain = float(self.sustain.get())
self.synth.release = float(self.release.get())
def _set_lfo(self):
self.synth.lfo_rate = float(self.lfo_rate.get())
self.synth.lfo_depth = float(self.lfo_depth.get())
def _set_cutoff(self):
self.synth.set_cutoff(float(self.cutoff.get()))
def _on_keydown(self, e):
# Modifier octaves
if e.keysym in ("Shift_L","Shift_R"):
self._octave = 12
return
if e.keysym in ("Control_L","Control_R"):
self._octave = -12
return
key = e.keysym.lower()
if key == "escape":
self.synth.all_notes_off()
return
if key in KEYMAP:
semis = KEYMAP[key] + self._octave
midi = self.synth.base_midi + semis
self.synth.note_on(midi)
def _on_keyup(self, e):
if e.keysym in ("Shift_L","Shift_R","Control_L","Control_R"):
self._octave = 0
return
key = e.keysym.lower()
if key in KEYMAP:
semis = KEYMAP[key]
midi = self.synth.base_midi + semis
self.synth.note_off(midi)
def main():
root = tk.Tk()
try:
style = ttk.Style()
style.theme_use("clam")
except Exception:
pass
app = SynthGUI(root)
root.protocol("WM_DELETE_WINDOW", root.destroy)
root.mainloop()
if __name__ == "__main__":
main()
How it works (brief tutorial)
- Audio callback (
sounddevice.OutputStream) pulls blocks of audio. - We loop through active voices (notes), generate the selected waveform, and shape it with the ADSR envelope.
- A vibrato LFO modulates pitch in semitones:
freq * 2^(depth/12 * sin(2πft)). - A simple one-pole low-pass smooths the output:
y += α(x − y). - Keyboard events (Tkinter) trigger
note_on/note_off. Polyphony uses a small voice pool with oldest-voice stealing.
Tips / Customizations
- Increase
MAX_VOICESfor more polyphony (CPU usage rises). - Change
BASE_MIDIto shift the keyboard’s base octave (e.g., 48 for C3). - Add chorus: duplicate voices with slight detune (
±5 cents). - Add echo: circular buffer with feedback for simple delay.
Related Posts


Previous Post
Next Post


Loading Next Post...